Your password isn’t as random as you think — Zipf’s law
Treat your password like your toothbrush. Don’t let anybody else use it, and get a new one every six months
-Clifford Stoll
Recently I got a mail to check whether any of my accounts have been breached. Have I been pwned is a site active since 2013 used to check whether any of your accounts have been compromised. So I went over there and typed in my password ….7 breached sites and 12 pastes! This doesn’t make any sense! So I dug in a little deeper to understand just how “hackable” my password truly was. Knowing full well that password guessing might not be the strategy adopted by a hacker, I had to figure out if all these passwords indeed were as random or did their occurrence have some inherent patterns. Chances are unless you are adding some sort of personal detail to your password it might already be in use by thousands of users across the world. To show this I’ve accumulated data from accounts of approximately 5 million users that got leaked. Bear in mind this data has been extracted and used strictly for research purposes.
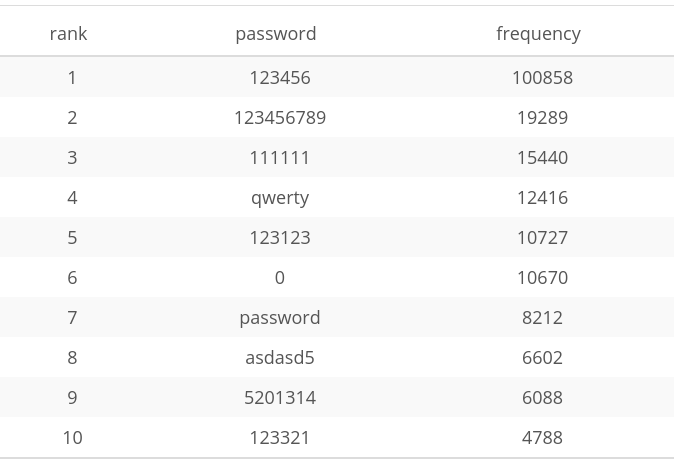
I’ve compiled a list of the most frequently used passwords. You might think that it requires extreme naivety to keep ‘123456’ as your password. It so happens that it is not only the most common password but also accounts for around 0.02% of all passwords. Also, common phrases such as ‘iloveyou’ (rank 85) and ‘fuckyou’ (rank 91) have been used with utter disregard of their own personal security.
But something real interesting came up when I plotted the frequency of these points against their ranks. Changed the scale to log and I found that the relationship was almost exactly linear. In fact, the R² statistic which determines the linearity of the data is 0.995 implying that it is highly linear.
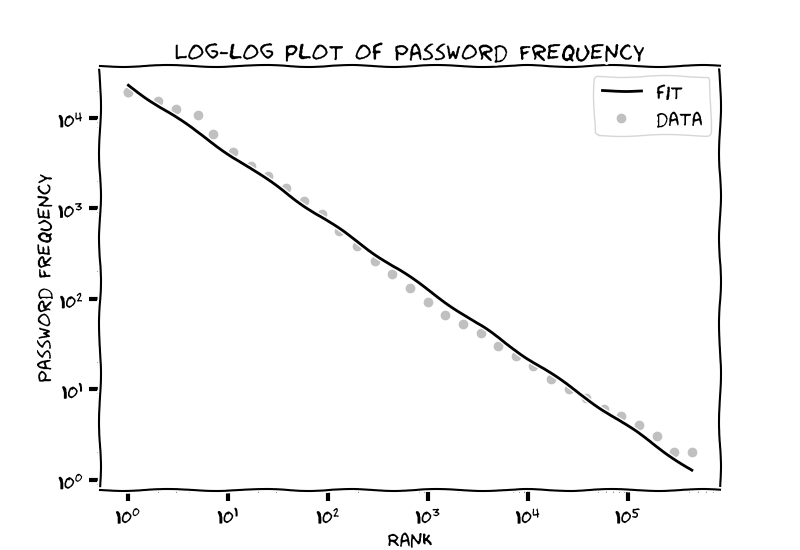
But what does this linear relationship on a log-log scale mean? Simply put,
Where $α$ is a number determined by the slope of the fit. This is commonly known as a power law. From the occurrence of earthquakes and stock market crashes to fractal patterns formed in shorelines and snow crystals such relationships are ubiquitous in nature. But is there any underlying reason for such a pattern to occur?
Enter Zipf’s Law
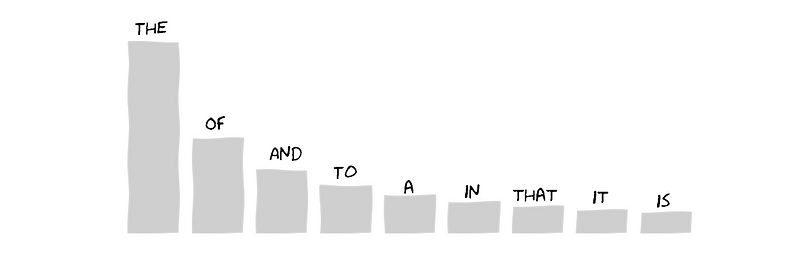
Let’s say you are to visit a library. Also for the sake of the argument let’s assume that all the books are written in English. Now you create a frequency chart as shown above where you count the frequency of each word that you come across while going through the books. You should find that the most common word is ‘the’. In fact, approximately 6-7% of the entire text should be ‘the’. The second most common word would be ‘of’ which would occur approximately half the number of times ‘the’ did (3–3.5%). The third most common word would be ‘and’ and it would have a frequency that is roughly a third of that of ‘the’. I think you can follow a trend here. The number of occurrences of a word depends on its rank in the frequency chart. Once you determine its rank the number of occurrences is simply the number of occurrences of ‘the’ divided by the rank.
Looking similar? Well, it should. This is exactly what we discussed before except over here $α=-1$.
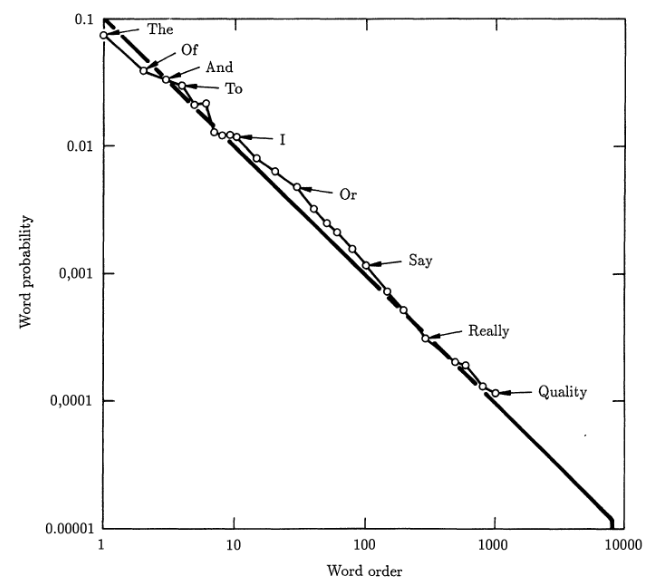
Is this true for any library? Yes provided it’s large enough and has a good mix of literature.
Is this true only for English? Such trends have been observed in pretty much all languages, even hieroglyphics!
This trend was popularized by George Kingsley Zipf and hence the name. To explain the law, Zipf proposed that human behavior follows the principle of least effort. He suggested that the power law was a necessary characteristic of language. It allows us to effectively communicate with the least effort. However, previously Mandelbrot had shown that this property isn’t simply limited to language. Consider large number of monkeys (infinite!) hitting the typewriter at random. These monkeys will end up producing a huge amount of text. This text will again follow Zipf’s law. I will keep that for discussion in another post. But how does this help us?
Compressing passwords
Larger the bias, higher the compressibility
This is essentially what Claude Shannon (founder of information theory) had shown. In other words, if all the English words had exactly the same frequency in a text we would require a lot more storage space to store it. The fact that it follows a certain frequency distribution (creating a bias in the text) can be used to encode it in a way that it uses less space. In fact, Shannon showed that we can use Zipf’s law of words to store it at a rate of 11.5 bits per words. This is known as the Shannon entropy rate. A word is on average 4–6 letters. This equates to almost 2 bits per letter. We know 2 bits equate to 4 possibilities. While the number of English alphabets — 26! We have essentially compressed it by 6 times.
The same can be done for the passwords. The Zipf’s law holds for almost 1 million of the most frequent passwords (this obviously is an overstretch but we’ll go with it for this analysis). The net frequency of these passwords accounts for almost 50% of all password occurrences.
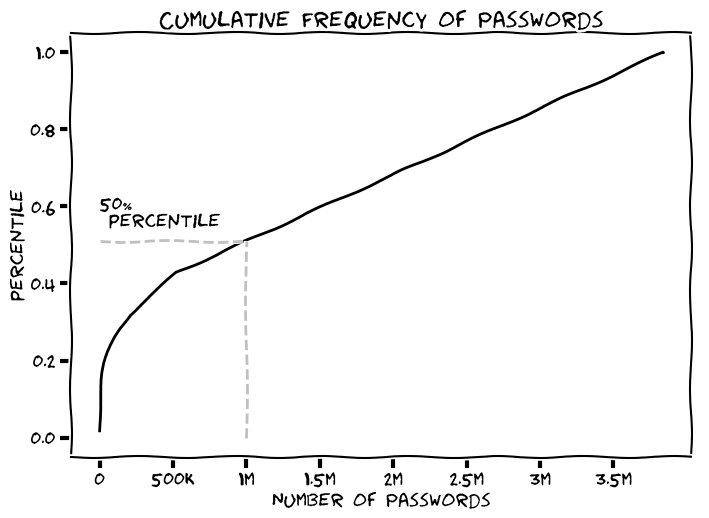
The Shanon Entropy for these passwords is 9.5 bits. Is that all? No. We still have to consider the remaining 50 percentile of passwords. So what other biases can we exploit?
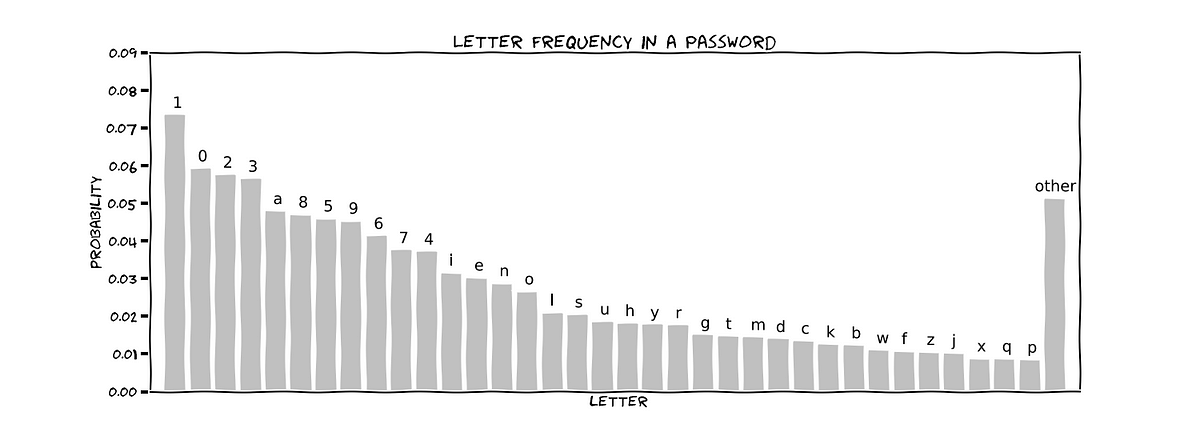
Not all the characters have been typed with the same probability. This is something that I had already observed in the data.
- Special characters are rarely used
- Most passwords are in small caps
- Digits are more commonly used than letters
You might want to consider these to make your password more unique. I found the Shanon entropy to be 5.2 bits per letter. Each character is stored as a Unicode hex character which is 8 bits. Hence we have compressed it by more than a third.
If we combine these 2 observations we find that we can reduce the size to around 30 bits per password as opposed to 64 bits per password (8 letters) on average. We have compressed it by more than 50%!
I think this says a lot about us as individuals capable of independent thought. The password is supposed to be something unique. The security of some very valuable personal information relies on it. And yet the password never turns out to be as unique.
Our thoughts and ideas aren’t inherently as independent as we might want it.
[1] D. Wang, G. Jian, X. Huang, P. Wang, “Zipf’s Law in Passwords” in IEEE Transactions on Information Forensics and Security 12(11):2776–2791 June 2017
[2] Manfred R. Schroeder, “Fractals, Chaos, Power Laws: Minutes from an Infinite Paradise”. Published July 15th, 1992 by W. H. Freeman
[3]G. K. Zipf: Human Behavior and the Principle of Least Effort (Addison-
Wesley, Cambridge, Mass).
Wesley, Cambridge, Mass).
[4]C. E. Shannon: “Prediction and entropy of printed English”. The Bell System Technical Journal ( Volume: 30, Issue: 1, Jan. 1951 )
Comments
Post a Comment